
00:00:00
prometheus tsdb (Part 1) - Head Block
一、概述
prometheus v2.0引入了tsdb,以下是tsdb的全局模型介绍:
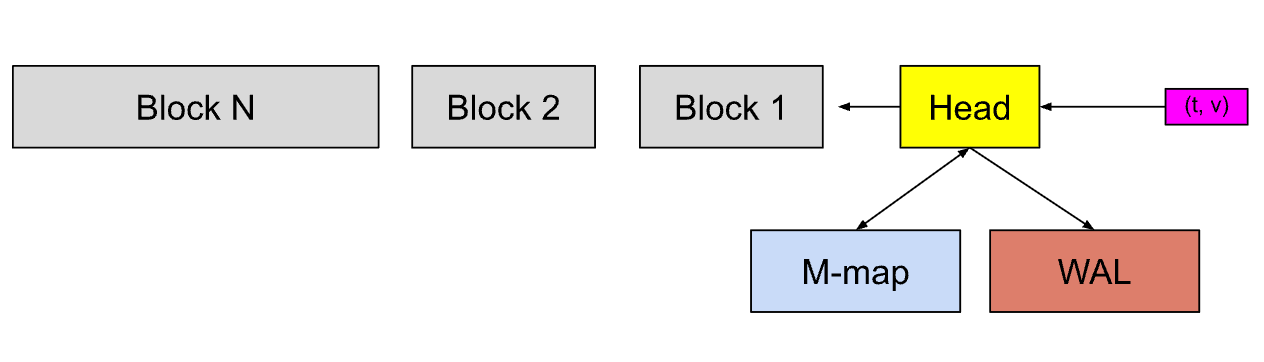
🧠 内存部分:Head Block
- Head block 是数据库中的内存部分,用于存储最新写入的数据。
- 每个新写入的样本(粉色框),首先会进入 Head block(即在内存中暂存)。
- 这是数据进入系统的第一站。
🧾 WAL(Write-Ahead Log)
- WAL 用于持久化写入日志,确保即使服务崩溃也能恢复数据。
- 每个样本在写入内存的同时也会写入 WAL。
- WAL 的存在让写入操作具备“先写日志,再更新内存”的安全性。
📦 磁盘部分:灰色块和蓝色块
- 内存中的数据在一段时间后会被
刷新(flush)到磁盘,形成灰色的持久化块(immutable blocks)。
- 刷新过程中会先生成
Memory-Mapped Chunks(蓝色块),即内存映射的中间状态。
🔁 块的生命周期管理
- 当蓝色块或内存块变“老”时,会被进一步刷新为磁盘上的持久块。
- 这些磁盘块是不可变的(immutable),不会再被更改。
- 多个旧块会被合并(merge),优化存储结构。
- 最终,当这些块超过设定的保留期(retention period),就会被自动删除。
✅ 总结流程
- 样本准备写入 → 内存 Head block
- 先写入 WAL 日志,保证持久性
- 再写入Head block
- 一段时间后,flush 为 memory-mapped chunks(蓝色)
- 再转化为磁盘持久块(灰色)
- 多个块合并压缩
- 到期后删除
二、Head block 样本寿命
以单个时间序列为例,适用于所有序列。
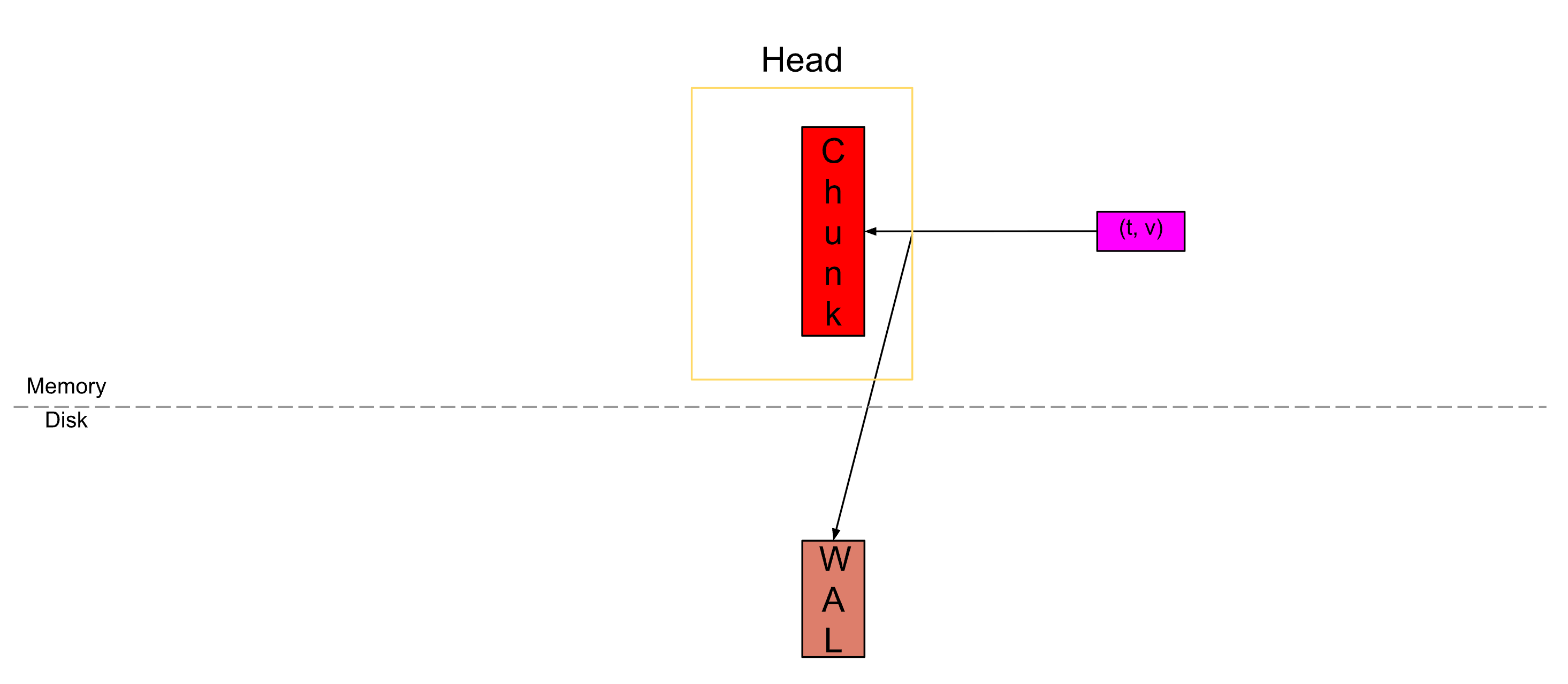
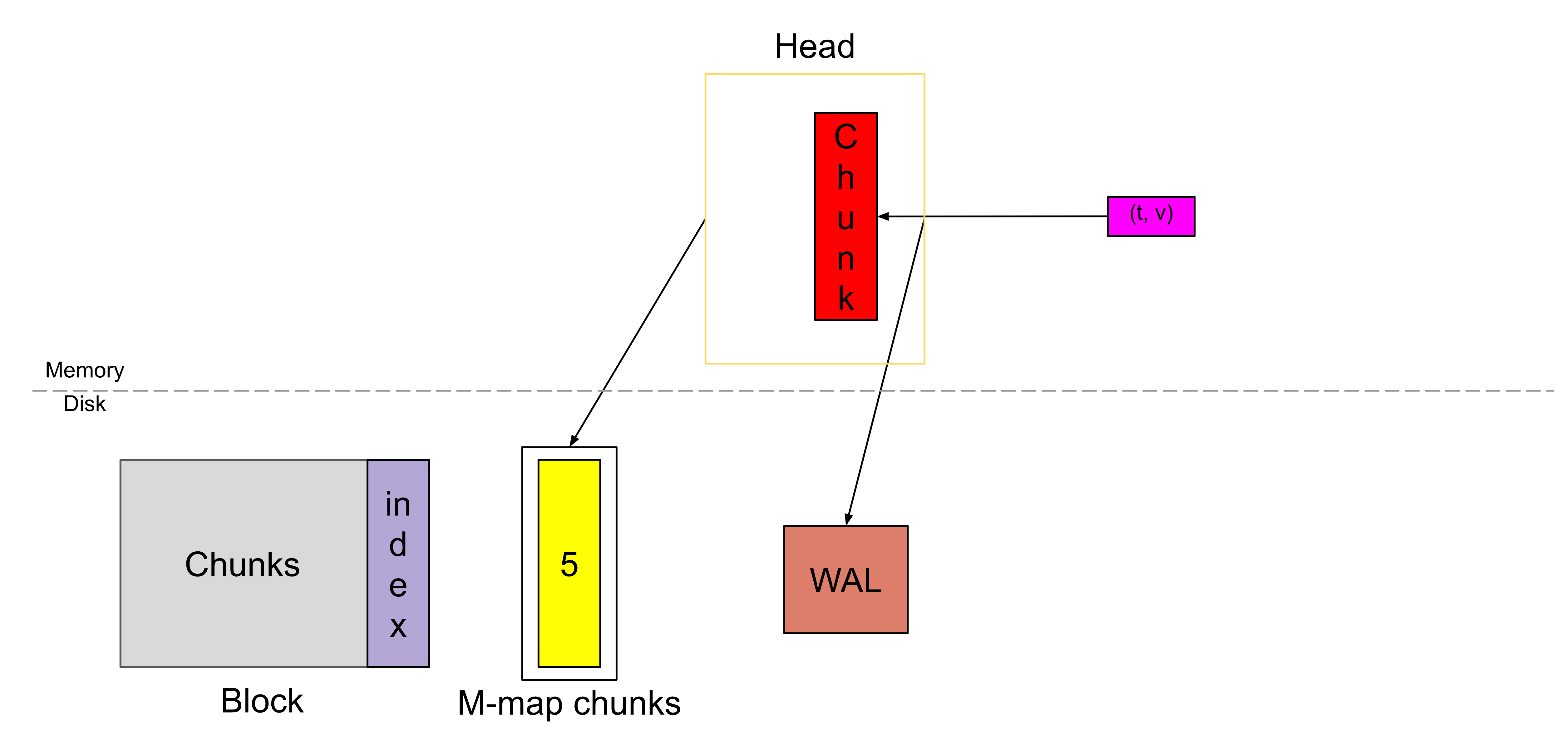
样本存储在称为“chunk”的压缩单元中。样本传入时,会被提取到“active chunk”(红色块)中。这是唯一可以主动写入数据的单元。
在将样本提交到chunk中时,我们还会将其记录在磁盘(棕色块)上的预写日志(Write-Ahead-Log ,简称WAL) 中,以实现持久性(这意味着即使机器突然崩溃,我们也可以从中恢复内存中的数据)。
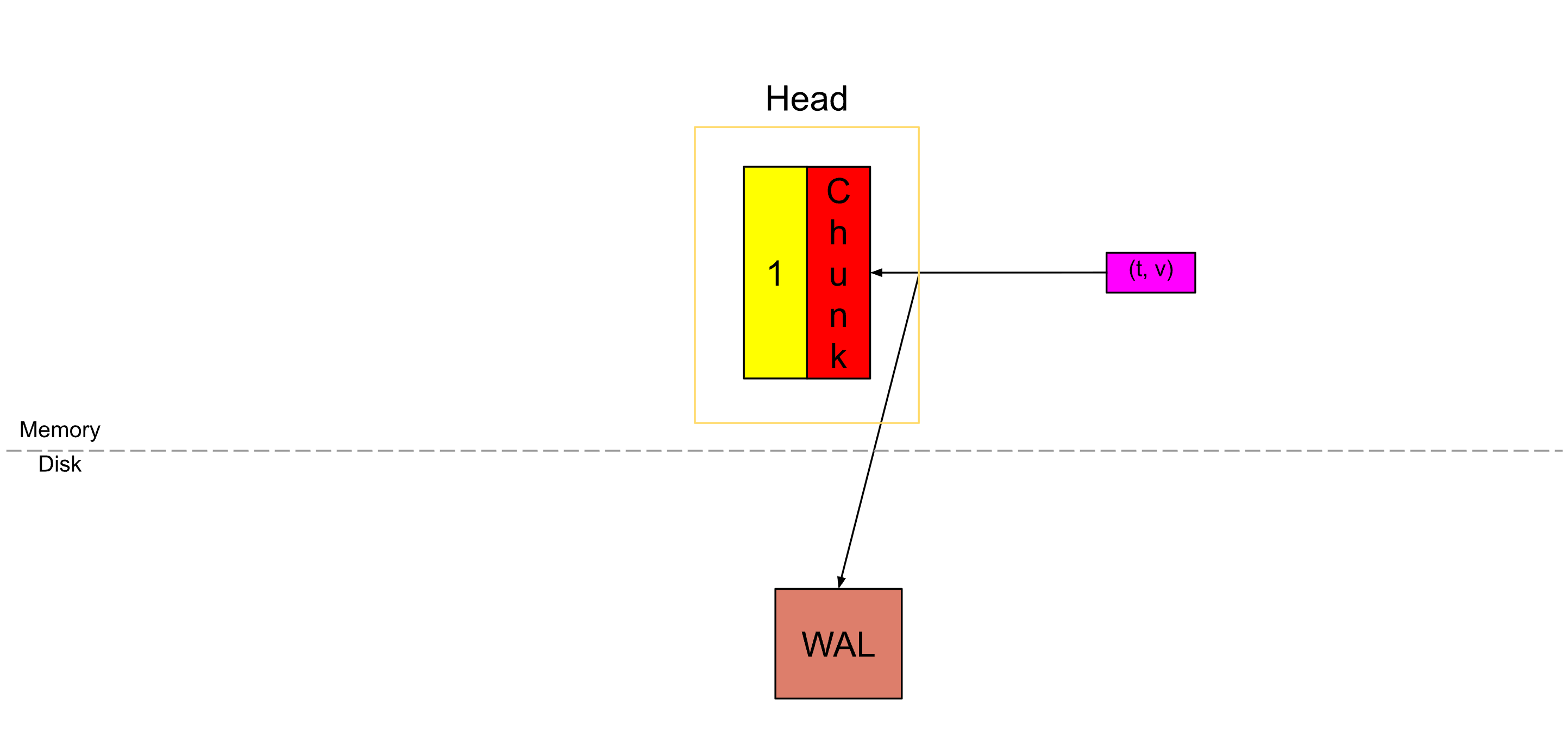
一旦一个块(chunk)填满了 120 个样本,或者跨越了 chunk/block 范围(这里我们称之为 chunkRange,默认是 2 小时),就会切割出一个新的块,而旧的块就被认为是“已满”的。
在这篇博客中,我们假设抓取间隔(scrape interval)是 15 秒,因此 120 个样本(一个完整的块)大约会覆盖 30 分钟。
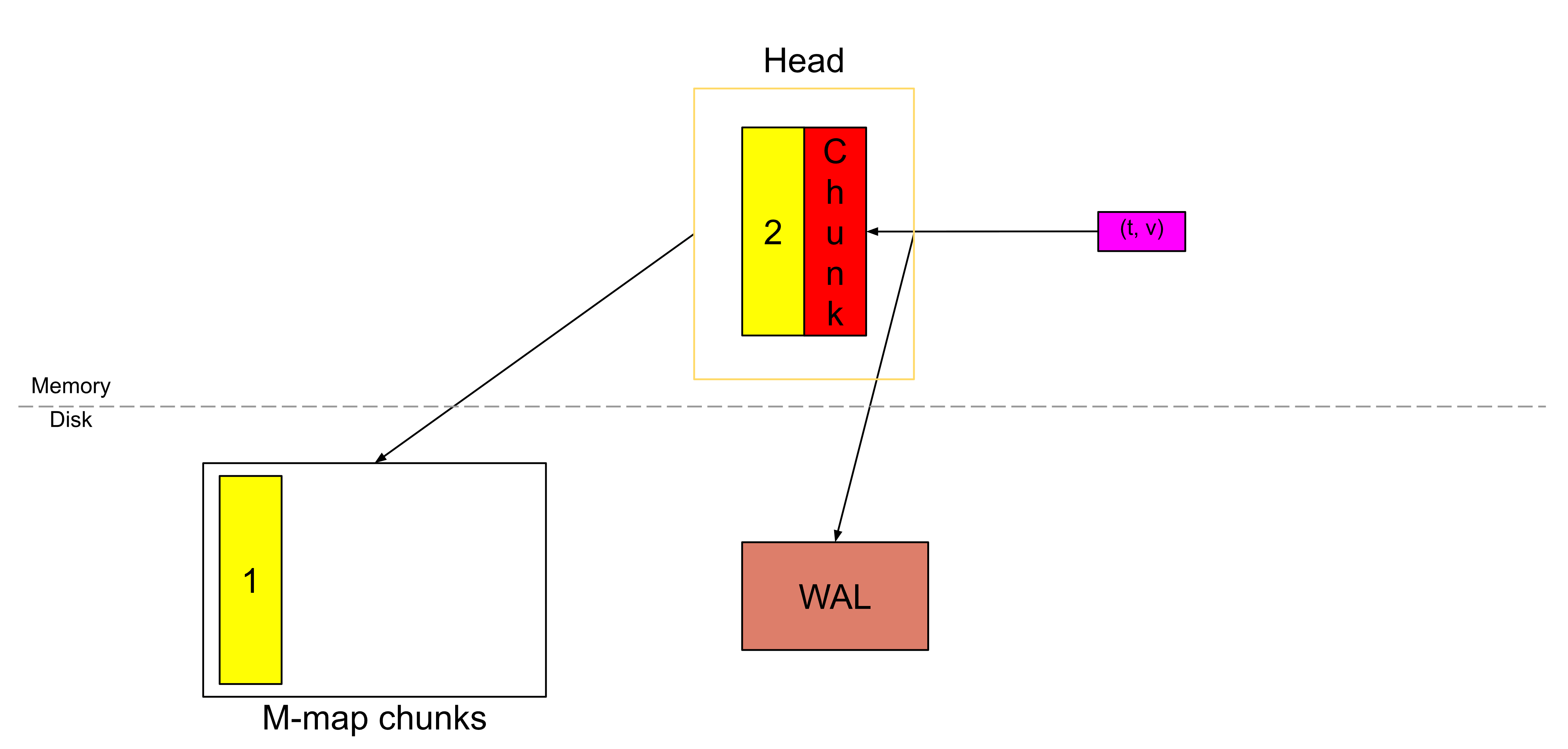
带有数字 1 的黄色块表示刚刚填满的完整块,而红色的块表示新创建的块。
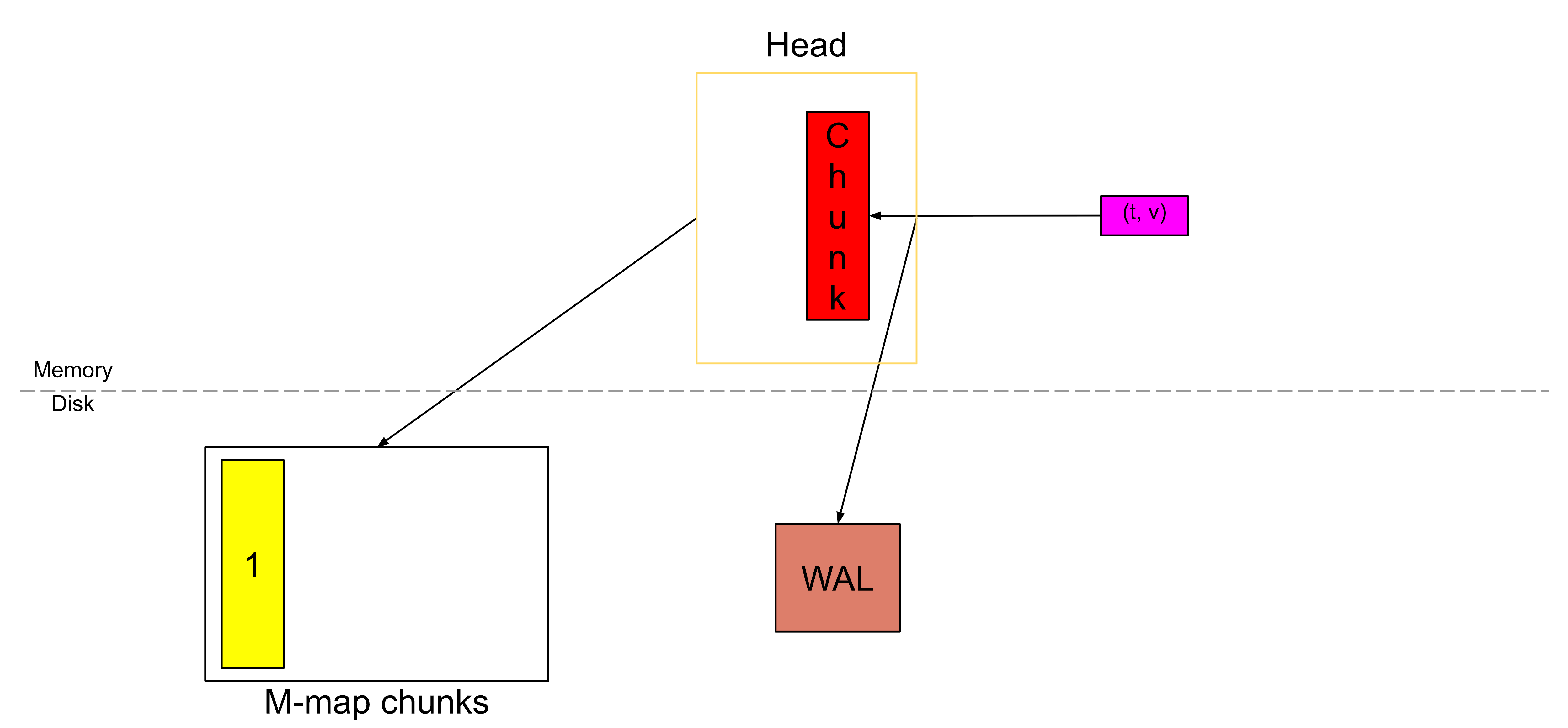
从 Prometheus v2.19.0 开始,我们不再把所有的块(chunk)都存放在内存中。
一旦切割出一个新块,已满的块就会被刷新到磁盘上,并通过内存映射(memory-mapping)的方式从磁盘加载,同时在内存中只保存一个引用。
借助内存映射,我们在需要时可以通过这个引用,把块动态地加载到内存中;这是操作系统提供的一种功能。
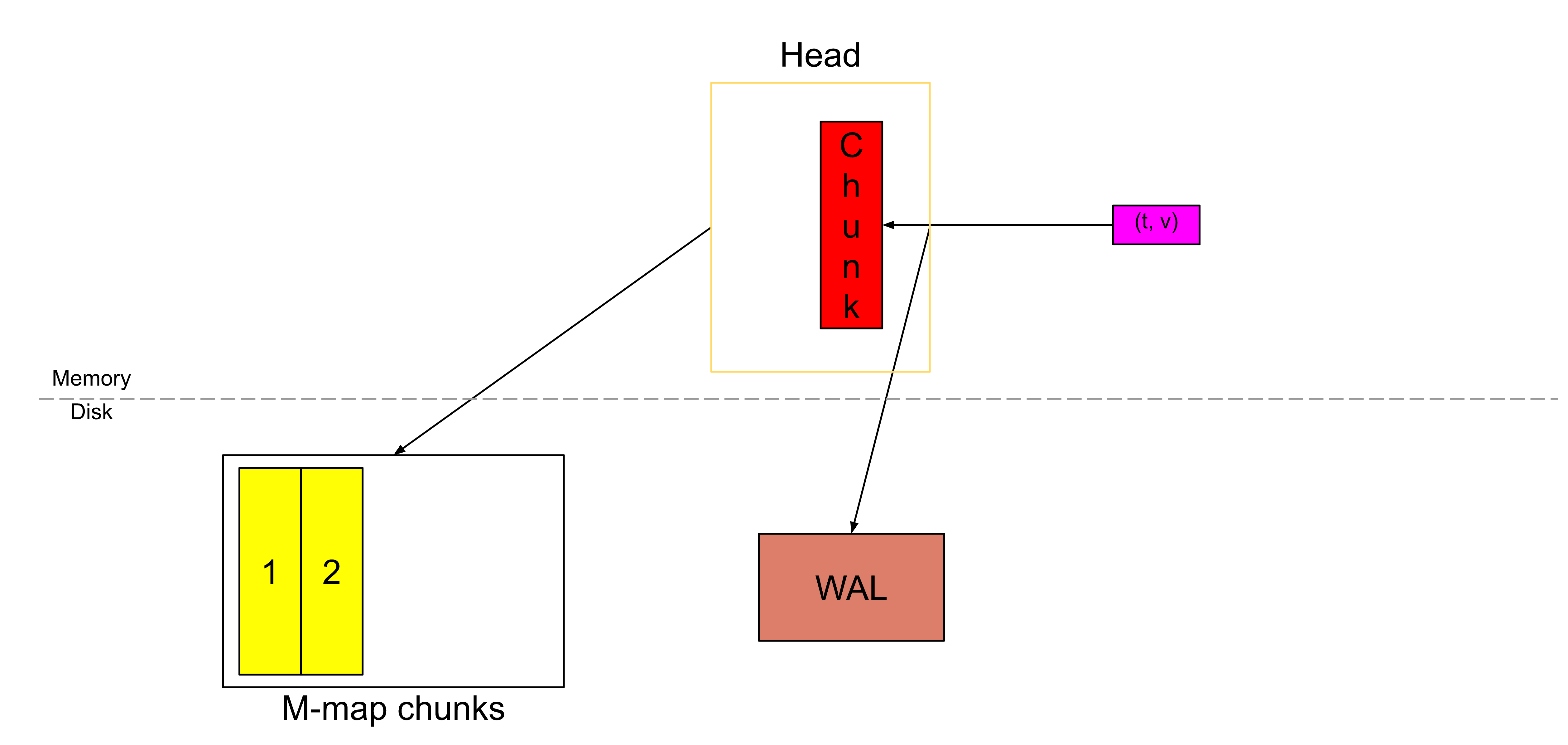
同样地,随着新的样本不断到来,就会不断切割出新的块(chunk)。
它们会被刷新到磁盘上,并通过内存映射的方式进行加载。
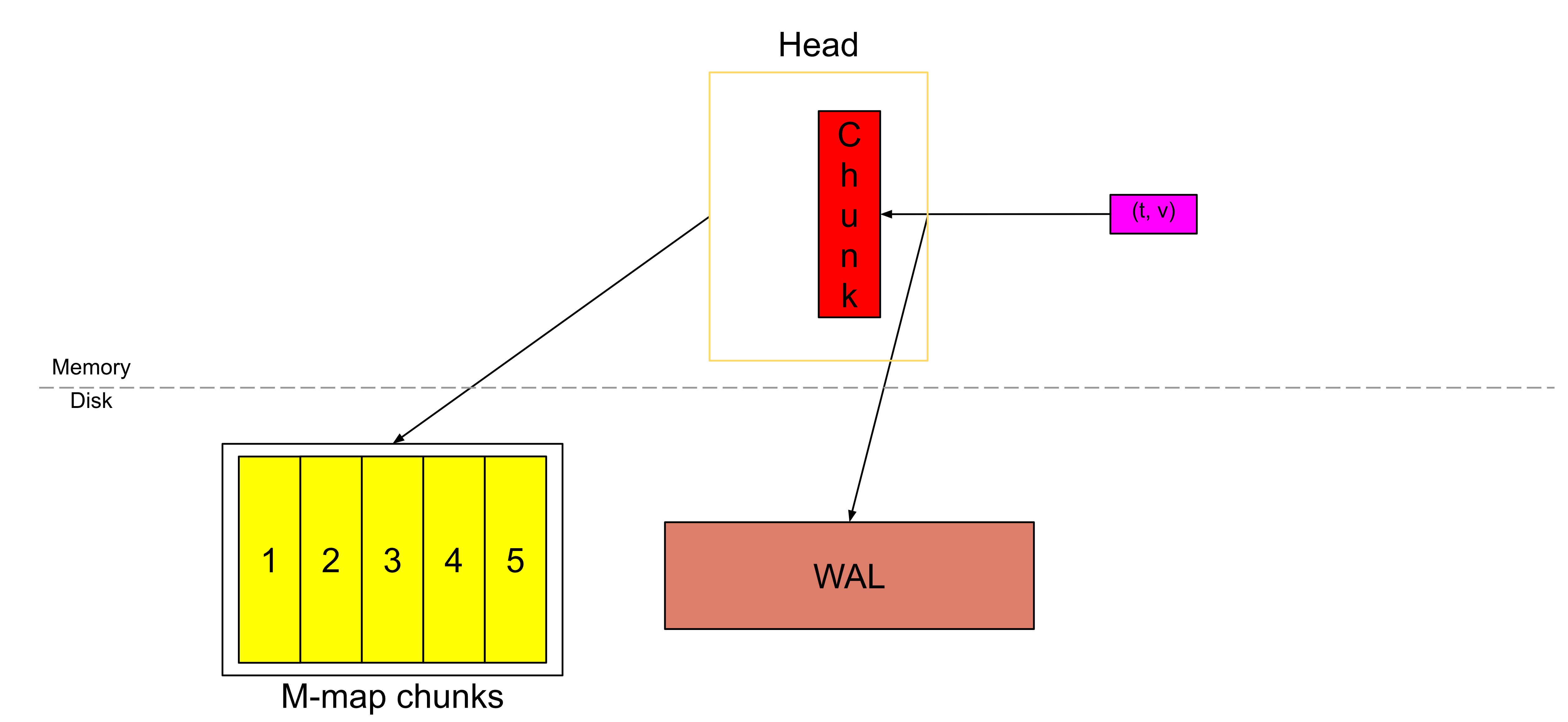
一段时间后,Head 块会像上图那样。假设红色的块已经快要填满,那么此时 Head 中就有 3 小时的数据(6 个块,每个块跨度为 30 分钟)。这相当于 chunkRange × 3/2。
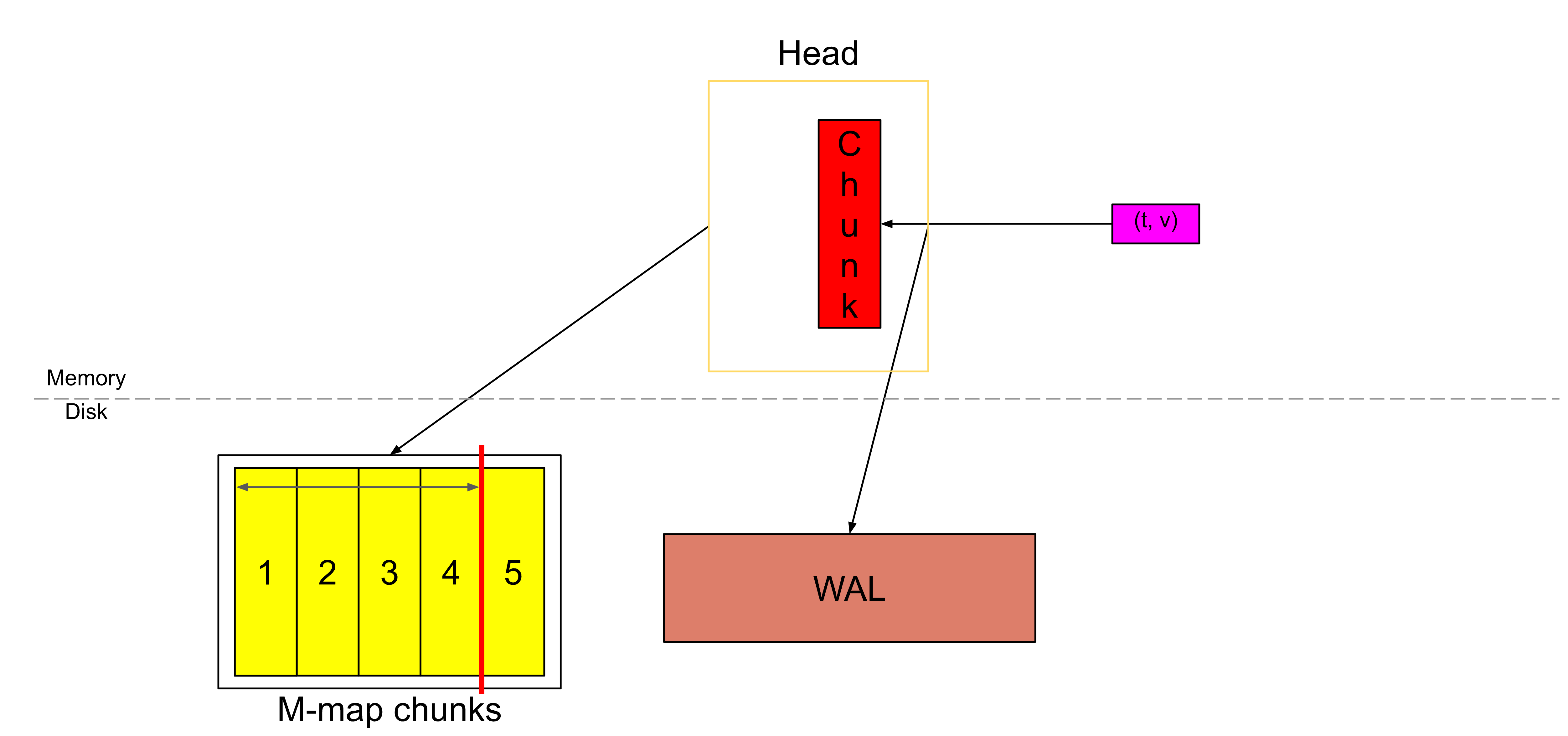
 当 Head 中的数据跨度达到 chunkRange × 3/2 时,最早的一个 chunkRange 的数据(这里是 2 小时)会被压缩(compacted)成一个持久化块(persistent block)。如果你注意到上文,这个时候 WAL(预写日志)会被截断(truncate),并创建一个“检查点”(checkpoint)(图中未展示)。我会在后续的博客中详细介绍 checkpoint、WAL 截断、压缩、持久化块以及它的索引。
当 Head 中的数据跨度达到 chunkRange × 3/2 时,最早的一个 chunkRange 的数据(这里是 2 小时)会被压缩(compacted)成一个持久化块(persistent block)。如果你注意到上文,这个时候 WAL(预写日志)会被截断(truncate),并创建一个“检查点”(checkpoint)(图中未展示)。我会在后续的博客中详细介绍 checkpoint、WAL 截断、压缩、持久化块以及它的索引。
这种数据的摄取(ingestion)、内存映射、压缩形成持久化块的循环会不断进行。而这正是 Head 块 的基本功能。
参考文献:
https://ganeshvernekar.com/blog/prometheus-tsdb-the-head-block/